
Version 0.8.0 of R’s fst package has been released to CRAN. The package is now multi-threaded allowing for even faster serialization of data frames to disk.
This post covers some of the enhancements that have been made to fst in the latest release and measures the performance against the serialization methods offered by packages feather and by base R itself. A parallel is drawn with the multi-threading enhancements recently added to data.table’s methods fread and fwrite for working with csv files. Also, some words on how and when to best use the fst binary format to benefit your workflow and speed up your calculations (and when not).
Table of Contents
Introduction
For a few years now, solid state disks (SSD’s) have been getting larger in capacity, faster and much cheaper. It’s not uncommon to find a high-performance SSD with speeds of up to multiple GB/s in a medium-end laptop. At the same time, the number of cores per CPU keeps growing. The combination of these two trends are opening up the way for data science to work on large data sets using a very modest computer setup.
The fst package aims to provide a solution for storing data frames on modern SSD’s at the highest possible speed. It uses multiple threads and compression to achieve speeds that can top even the fastest consumer SSD’s that are currently available. At the same time, the fst file format was designed as a random access format from the ground up. This offers a lot of flexibility and allows reading subsets of data frames (both columns and rows) at high speeds.
Below you can see just how fast fst is. The benchmark was performed on a laptop with a mid range CPU (i7 4710HQ @2.5 GHz) and a reasonably fast (NVME) SSD (M.2 Samsung SM951). The data sets used for measurement were generated on the fly and consists of various column types (the data set is defined below). The number of threads (were appropriate) was set to 8.
| Method | Format | Time (sec) | Size (MB) | File Size (MB) | Speed (MB/s) |
|---|---|---|---|---|---|
| readRDS | bin | 1.57 | 1000 | 1000 | 633 |
| saveRDS | bin | 2.04 | 1000 | 1000 | 489 |
| read_feather | bin | 3.95 | 1000 | 812 | 253 |
| write_feather | bin | 1.82 | 1000 | 812 | 549 |
| read_fst | bin | 0.45 | 1000 | 303 | 2216 |
| write_fst | bin | 0.28 | 1000 | 303 | 3559 |
Table 1: read and write performance of fst, feather and baseR binary formats
The table compares method write_fst to it’s counterparts write_feather and saveRDS. Method read_fst is compared to it’s counterparts read_feather and readRDS. For saveRDS, the uncompressed mode was selected because the compressed mode is very slow (a few MB/s only).
As can be seen, a write speed of more than 3.5 GB/s was measured for write_fst. That speed is higher than the speed reported in the drive’s specifications (about 1.2 GB/s) due to the magic of compression. Because data is compressed before it’s written to disk, there is less actual data transported from the CPU to the SSD, greatly boosting write (and read) speeds.
After introducing some of the basic features of fst, we will get back to these benchmarks and take a look at how the package uses a combination of multi-threading and compression to effectively boost the performance of data frame serialization.
Put fst to work
The package interface for serialization of data frames is quite straightforward. To write a data frame to disk:
library(fst)
write_fst(df, "sampleset.fst") # write using default compression
This writes data frame df to a fst file using the default compression setting of 50 percent. If df is a data.table, the key columns (if any) are also preserved. To retrieve the stored data:
df_read <- read_fst("sampleset.fst") # read a fst file
That’s all you need for basic functionality!
In addition, the fst file format was especially designed to provide random access to the stored data. To retrieve a subset of your data you can use:
df_read <- read_fst("sampleset.fst", c("A", "B"), 1000, 2000)
This reads rows 1000 to 2000 from columns A and B without actually touching any other data in the stored file. That means that a subset can be read from file without reading the complete file first. This is different from, say, readRDS or read_feather where you have to read the complete file or column before you can make a subset.
This ‘on-disk subsetting’ takes less memory, because memory is only allocated for columns and rows that are actually read from disk. Even with a fst file that is much larger than the amount of RAM in your computer, you can still read a subset without running out of memory!
The graph below depicts the relation between the read time and the amount of rows selected from a 50 million row fst file. As you can see, the average read time grows with the amount of rows selected. Reading all 50 million rows takes around 0.45 seconds, the value reported in the table in the introduction.
 Figure 1: Time required for reading a subset of a stored data set
Figure 1: Time required for reading a subset of a stored data set
Some basic speed measurements
The read and write speed of fst depends on the compression setting and the number of threads used. To get an idea about these dependencies we generate a data set containing various column types and do some speed measurements:
nr_of_rows <- 5e7 # use 50 million rows
df <-
data.frame(
# Logical column with mostly TRUE's, some FALSE's and few NA's
Logical = sample(c(TRUE, FALSE, NA), prob = c(0.85, 0.1, 0.05), nr_of_rows, replace = TRUE),
# Integer column with values between 1 and 100
Integer = sample(1L:100L, nr_of_rows, replace = TRUE),
# Real column simulating 'prices'
Real = sample(sample(1:10000, 20) / 100, nr_of_rows, replace = TRUE),
# Factor column with US cities
Factor = as.factor(sample(labels(UScitiesD), nr_of_rows, replace = TRUE))
)
This data set was also used to obtain the benchmark results reported above. To get accurate timings for writing to disk we use the microbenchmark package
library(microbenchmark)
# perform a single measurement only to avoid disk caching
write_speed <- microbenchmark(
write_fst(df, "sampleset.fst"),
times = 1
)
# speed in GB/s
as.numeric(object.size(df)) / write_speed$time
## [1] 3.55976
As we saw earlier, the measured write speed (about 3.5 GB/s) is much higher than the maximum write speed of the SSD. This is possible because the actual amount of bytes that where pushed to the SSD is lower than the in-memory size of the data frame because of the compression used (less data == more speed):
# compression ratio:
as.numeric(file.size("sampleset.fst") / object.size(df))
## [1] 0.3007902
The file size is about 30 percent of the original in-memory data frame size, the result of using a default compression setting of 50 percent. Apart from the resulting speed increase, smaller files are also attractive from a storage point of view.
Multi-threading
Like data.table, the fst package uses multiple threads to read and write data. So how does the number of threads affect the performance? You can tune multi-threading with:
threads_fst(8) # allow fst to use 8 threads
With more threads fst can do more background processing such as compression. Obviously, setting more threads than there are (logical) cores available in your computer won’t help you (in most cases).
The graph below shows measurements of the read- and write speeds for various ‘thread settings’ and number of rows. Sample sizes of 10 million and 50 million rows were used.
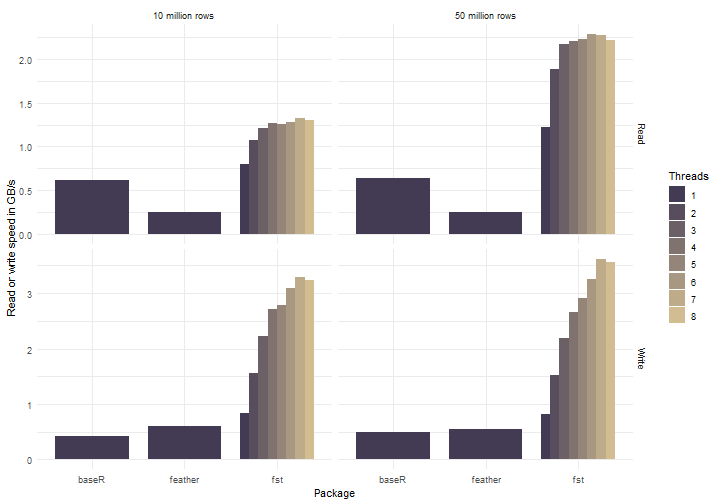 Figure 2: Binary read and write speed for packages fst, feather and for base R
Figure 2: Binary read and write speed for packages fst, feather and for base R
The effects of multi-threading are quite obvious and fst does well in both reading and writing (note that the bar corresponding to Threads == 1 is basically fst before version 0.8.0). A top write speed of 3.6 GB/s was measured using 7 threads. My laptop only has 4 physical cores, but increasing beyond 4 threads still increases performance (hyper threading does work in some cases :-)).
The measured read speeds are lower than the write speeds although the SSD has a higher read throughput according to the specifications. This probably means that there is room for some more improvements on the read speeds when the code is further optimized.
The way fst uses multiple threads to do background processing is similar to how the data.table packages employs multiple threads to parse and write csv files. Below is a graph comparing fread/fwrite to it’s counterparts read.csv2/write.csv2 (package utils) and read_csv/write_csv (package readr):
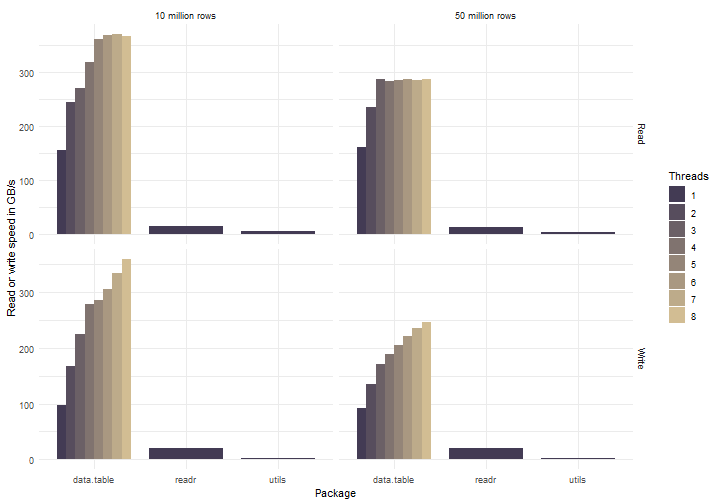 Figure 3: Read and write speed of csv files as measured for packages data.table, readr and utils (base R)
Figure 3: Read and write speed of csv files as measured for packages data.table, readr and utils (base R)
The data.table package is an order of magnitude faster than the competing solutions from utils and readr. Even when only a single thread is used, the speed difference is quite large. This is all due to the excellent work of the people working on the data.table package. The parallel implementations of fwrite and fread were created recently and they are clearly very fast, an impressive piece of work!
When to use the fst format and when to stick with csv
The csv format is a common data exchange format that is widely supported by consumer, business, and scientific applications. It’s human-readable, can be edited with a simple text editor and can be used cross-platform and cross-language. And if you use the data.table package to read and write your csv, it’s fast as well.
Despite these obvious advantages, there are some things you can’t do with csv but you can by using the fst (binary) format:
- With a csv it’s hard to read a single column of data without parsing the rest of the information in the rows (because the csv format is row-oriented). By contrast, the fst format is column-oriented (as is the feather format) so selecting specific columns requires no overhead.
- Reading a selection of rows from a csv requires searching the file for line-ends. That means you can never have true random-access to a csv file (a search algorithm is needed). In fst, meta data is stored that allows for the exact localization of any (compressed) element of a data set, enabling full random-access.
- You can’t add columns to a csv file without rewriting the entire file.
- You can’t store information from memory to csv (and vice versa) without first (de-)parsing to human-readable format. On other words, no zero-copy storage is possible. The fst format is a zero-copy format and in general no parsing is required to transfer data to and from memory, except for (de-)compression.
To sum up, this all means that storing your data with fst will in general be faster and more compact than storing your data in a csv file, but the resulting fst file will be less portable and non human-readable. Whether you are best of using a csv or fst file depends on your specific use case. csv is king especially for small data sets where the serialization performance is already adequate. But if you need more speed, more compact files or random access, fst can help you with that.
How compression helps to increase performance
The maximum write- and read speeds of a (solid state-) disk are a given. Any write- or read operation to and from disk will be bound by that maximum speed, there’s not much you can do about that (except buy a faster disk).
However, the amount of data that goes back and forth between the disk and your computer memory can be reduced by using compression. If you compress your data with, let’s say, a factor of two, the disk will probably spent about half the time on reading or writing that data (less data == more speed). The downside is that the compression itself will also take CPU time, so there is a trade-off there that depends on the speed of the disk and the CPU speed.
How does that work? Suppose a disk has an extremely high speed, then any amount of compression will lower the total speed of writing data to that disk. On the other hand, when the disk has a very low speed (say a network drive), any amount of compression would actually increase the total speed. Most setups will have maximum performance somewhere in between.
To shift the balance, the fst package uses multi-threading to compress data ‘in the background’, so while the disk is busy writing data. Using that setup, it’s possible to saturate your disk and still compress data, effectively increasing the observed write (and read) speed. The figure below shows how compression impacts the performance of reading and writing data to disk.
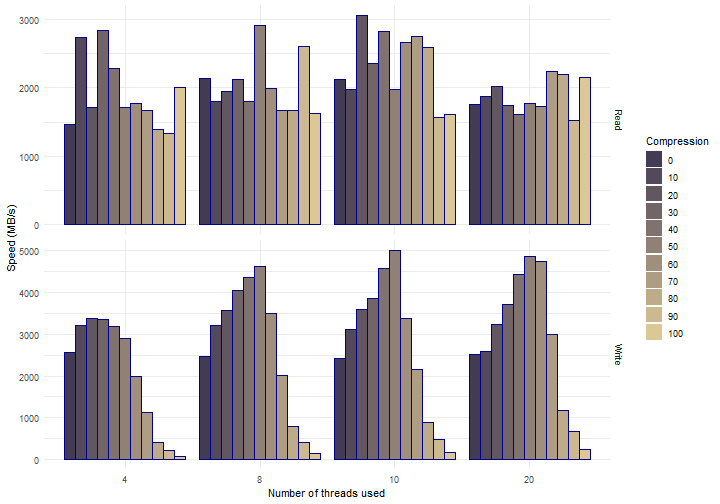 Figure 4: Compression and decompression speed depends on compression level settings
Figure 4: Compression and decompression speed depends on compression level settings
These measurements were performed on a Xeon E5 CPU machine (@2.5GHz) that has 20 physical cores (with more cores, it’s easier to see the scaling effects). The horizontal groups in the figure represent the different amount of threads used (4, 8, 10 and 20). Vertically we have the read and write speeds. The colors represent various compression settings in the range of 0 to 100 (so not the number of threads like in the previous graph). Compression helps a lot to increase the maximum write speed. If enough cores are used, the background compression can keep up with the SSD and the total write speed will increase accordingly (less data == more speed). The same could be expected to be true for the read speed. The effects seem to be minimal however and some more thinking is required to bring the read speed at the same level as the write speed (perhaps we need parallel file connections, larger read blocks or different multi-threading logic? ideas are very welcome :-)).
Per-column compression optimalization
The fst package uses the excellent LZ4 compressor for high speed compression at lower ratio’s and the ZSTD compressor for medium speed compression at higher ratio’s. Compression is done on small (16kB) blocks of data, which allows for (almost) random access of data. Each column uses it’s own compression scheme and different compressors can be mixed within a single column. This flexible setup allows for better optimized and faster compression of data.
Note: there is still much work to be done to further optimize these compression schemes. The current version of the fst package is using ‘best (first) guess schemes’. Following more elaborate benchmarks in the future, these schemes will be fine-tuned for better performance and new compressors could also be added (such as dictionary based compressors optimized for text or bit-packing compressors for integers).
All compression settings in fst are set as a value between 0 and 100 (‘a percentage’). That percentage is translated into a mix of compression settings for each (16kB) data block. This mix is optimized (and will be more so in the future :-)) for that particular data type. For example, at a compression setting of 30, data blocks in an integer column are a mix of 40 percent uncompressed blocks and 60 percent blocks compressed with LZ4 + a byte shuffle. The byte shuffle is an extra operation applied before compression to speed things up. That only works because we know we are dealing with an integer column (byte shuffling a character column wouldn’t help at all). That means that we can use information about the specific column type to enhance the compression. This is a unique feature of fst that has a huge positive impact on performance.
More on fst’s features
If you’re interested in learning more on some of the new features of fst, you can also take a look at these posts:
Final note
With CRAN release v0.8.0, the fst format is stable and backwards compatible. That means that all fst files generated with fst package v0.8.0 or later can be read by future versions of the package.
Thanks for making it to the end of my post (no small task) and for your interest in using fst!
This post is also available on R-bloggers

